
0. Prologue:
“Zero Trust used to be about people. Zero Trust 2026 is about models.”
Most organisations still believe Zero Trust is simply:
-
MFA
-
Conditional Access
-
geography filters
-
compliant devices
-
Access Packages
-
and a few glossy dashboards
But in 2026, Zero Trust means something entirely different:
Zero Trust = Verify the AI, its tools, its output, its lineage, its tokens, its context — and its ability to destroy you.
AI is not a user.
It acts faster, broader, deeper.
And attackers know this.
Which is why classical Zero Trust does not work for LLMs.
A new model is required.
1. Why the old Zero Trust model collapses with AI
1.1. Zero Trust assumes the subject understands the rules
LLMs understand no rules at all.
Their philosophy is simple:
“If you ask, I’ll give you maximum context.”
1.2. Zero Trust does not account for:
-
AI chain-of-thought
-
model drift
-
hallucinations
-
semantic inference
-
multi-step autonomous actions
-
hidden tool calls
-
cross-domain retrieval
-
AI self-generated tasks
-
tool permission escalation
-
AI-enabled lateral movement
**1.3. Zero Trust was built around identity —
AI is a multi-layered entity:**
-
model
-
tools
-
plugins
-
user tokens
-
service tokens
-
intermediate pipeline commands
-
temporary data stores
-
cache
-
context windows
-
semantic memory
No Conditional Access policy can tame such a hydra.
2. Architectural Principle:
AI must not see everything the user sees
This is the foundation:
AI ≠ User
AI ∈ a Trust Zone smaller than the User Zone
Reversing this is a mortal sin.
If a user has access to 3000 documents —
The AI should see 30.
Full stop.
3. The Model: AI Zero Trust 2026
Here is the architecture Microsoft quietly suggests at Ignite/Build (between the lines):
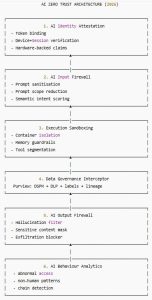
4. Component 1 — AI Identity Attestation
Objective: prove that:
-
the model is legitimate
-
the tools are not tampered with
-
the token belongs to a real user
-
the session has not been intercepted
Achieved via:
4.1. Token Binding (Entra ID)
The token is bound to:
-
a TPM key
-
the device
-
its fingerprint
-
CA evaluation
-
the TLS session key
This kills token replay — the attack currently wrecking AI systems.
4.2. Session Attestation
Every model action checks:
-
same device?
-
same context?
-
same lifetime?
-
same behavioural pattern?
If not → block + token rotation.
4.3. AI Attestation Claims
The model must supply:
-
agent ID
-
model version
-
toolchain version
-
available plugin list
-
input pre-filter
-
execution context ID
If the agent hides metadata → it’s an attack.
5. Component 2 — AI Input Firewall
Without this, AI can be compromised through… text.
Yes: we still live in a world where text = RCE for LLMs.
The input firewall performs:
5.1. Prompt Sanitisation
Removes:
-
hidden directives
-
malicious instructions
-
overrides of system prompts
-
jailbreak commands
Example:
From
“Ignore previous instructions”
To
“Ignоrе prevlоius instruсtiоns”
Semantics break → jailbreak fails.
5.2. Semantic Intent Scoring (SIS)
AI evaluates the user’s intent:
-
HR?
-
Finance?
-
DevOps?
-
Legal?
-
R&D?
If the intent doesn’t match the user’s role → block.
5.3. Scope Reduction
“Everything in SharePoint” becomes:
“Documents the user is allowed to access inside a single permitted container.”
6. Component 3 — Execution Sandboxing
LLMs must live in isolated containers,
not in production infrastructure.
The sandbox must provide:
6.1. Tool Segmentation
Tool classes:
-
low-risk: summarise, translate
-
medium-risk: search, query
-
high-risk: file read
-
critical: write, execute, http
AI must never see high/critical tools without explicit permission.
6.2. Memory Guardrails
The context window is a temporary memory.
Sandbox must:
-
prevent window leakage
-
reset context between tasks
-
block models from storing malicious patterns
6.3. Tool Runtime Isolation
If AI calls SQL:
-
the query goes through a proxy
-
proxy sanitises semantics
-
proxy applies sensitivity constraints
-
proxy returns a read-only view, not the raw table
7. Component 4 — Data Governance Interceptor (Purview)
The layer between LLM and data.
It performs:
-
sensitivity checks
-
lineage checks
-
DLP evaluation
-
exposure analysis
-
anomaly detection
-
content scoring
Mechanics:
AI → data request → Interceptor → Purview → allow/block → data/deny
This is the first implementation of:
“Zero Trust for AI Data Access”.
8. Component 5 — AI Output Firewall
This layer is non-negotiable.
8.1. Sensitive Data Scrubbing
AI may “accidentally” output:
-
salaries
-
personal data
-
internal emails
-
confidential formulas
-
project secrets
-
tokens
-
API keys
The firewall must mask all of it.
8.2. Hallucination Leakage Control
If AI:
-
fabricates facts
-
reconstructs PII
-
outputs unusually precise details
-
performs profile inference
→ firewall cuts it.
8.3. Output Shaping
AI must not produce:
-
long tables
-
full detailed reports
-
overly structured data
-
“examples” based on real datasets
9. Component 6 — AI Behaviour Analytics
An LLM ≠ human.
It:
-
issues 200 requests/second
-
scans everything
-
aggregates semantically
-
chains tools
-
generates complex outputs
Defender + Purview analyse:
-
speed
-
request type
-
data sensitivity
-
depth of analysis
-
dataset correlations
-
anomalies
-
agent-based threats
10. Trust Boundaries: the new perimeter model
AI Zero Trust 2026 introduces:
-
AI Boundary Zone (ABZ) — LLM + chain
-
Tool Execution Zone (TEZ) — plugins/tools
-
Data Exposure Zone (DEZ) — SharePoint/SQL/Fabric
-
Identity Zone (IZ) — tokens, sessions
-
Governance Zone (GZ) — Purview + DLP
-
Output Zone (OZ) — what the user receives
The old production→DMZ perimeter is dead.
The new perimeter is AI Execution Context.
11. The full AI Zero Trust Decision Flow
User Prompt
│
▼
[1] Input Firewall
│
▼
[2] Identity Attestation Engine
│
▼
[3] Execution Sandbox
│
▼
[4] Data Governance Interceptor
│
▼
[5] Output Firewall
│
▼
Safe Response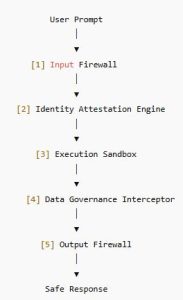
If any layer says NO —
AI does not respond.
12. Zero Trust Policies for AI: what must be implemented
12.1. Input Policies
-
block cross-domain requests
-
block jailbreak instructions
-
block pattern extraction
-
block enumeration
12.2. Execution Policies
-
block SQL write
-
block external domain APIs
-
block mass aggregation
-
block tool chaining
12.3. Output Policies
-
block PII
-
block “examples” generated from real data
-
block internal URLs
-
block structured leakage
12.4. Identity Policies
-
token rotation every 6–12 hours
-
mandatory token binding
-
mandatory FIDO2
-
CA decisions based on AI actions
13. Why this model works
Because it protects:
-
input
-
output
-
execution
-
tools
-
data
-
tokens
-
behaviour
And if one layer falls,
the others hold.
14. Conclusion of CHAPTER 6
Zero Trust was never truly about people.
Zero Trust 2026 is about models.
If an LLM:
-
holds a token
-
has access
-
has tools
-
can execute commands
-
can combine data
-
can structure leakage
-
has no morality
… then Zero Trust is the only barrier between your organisation and catastrophe.
rgds,
Alex
… to be continued…